2025-05-20
ゴム試料の海洋生分解性に関する実験で得られた試験結果を、ディープラーニング処理を用いることで、要求されるゴム特性と環境性能の両方を達成する最適なコンパウンドを探索しました。日本ゴム協会年次大会での口頭発表内容の詳細版です。
限られた実験データを深層学習処理することで、次の実験に向けた有力な示唆出しを行うことを目標として実施しました。タイヤゴムの開発における以下の前提に基づき、古典的な統計推論や実験計画法ではなく、深層学習によるアプローチで探索することにしました。
①実務上実験数はある程度限定されてしまう
②産業用途を想定したゴム物性においては、両立しづらい複数の特性を実現する必要がある。複数の環境性能に加えて、複数走行性能を実現する必要がある
③ゴム製造条件は相当程度の要因による
今回深層学習を用いることにした理由として、①より少ないデータから、②より複雑な検討をすることができ、③それを学習的に運用できる点があります。以下は、従来の統計推論・実験計画と、深層学習を用いたモデルベース開発との違いです。
人的考察
古典的統計推論
機械学習による推論
深層学習を用いた
モデルベース開発
メリット
コスト
統計的厳密さで
古典的査読には通りやすい
大量データ処理による
安定的な推論
少ない実験から人間の想定以上の示唆が出せる
推論の新規性
ある
乏しい
少ない
データ量
(実験数)
量が多少増えると
対応できない
ある程度の量が必要
大量に必要なことが多い
最近は少量でも可
大量なら尚よし
交互作用
2次~3次程度
4次以上をカバーすることは稀
通常3次まで
9次程度まで(実績)
モデルの前提
原因は一つ、モデルは一つという想定
多原因モデルを想定
モデルの変更
カンと経験
硬直的で新たに組み直す必要がある
柔軟に学習的に対応可能
想定外の使われ方
弱い
強い
弱いことも多い
デメリット
人的継承が困難
実務上意義のある示唆が出ることは稀
特徴量エンジニアリングが必要で面倒
モデル構築・学習における高度なデータ科学が必要
全体のフレームワークは以下の工程です。
実験条件から成る実験データから87因子を取り出し、評価結果のうち11の優先項目を取り出して、よりよい条件の探索を行いました。
↓
開発においては画像データもありましたが、今回は中心となる表形式のデータのみを用いました。
実現するゴム性能や環境性能が複数あるため、多目的最適化手法を用いました。手法としては、
①深層学習モデルのハイパーパラメータ最適化
②セットベース設計法
の2点です。
経過としては①で目標値の獲得ができなかったために②を補完・代替的に用いたという経過です。
①においては、ヒューリスティック最適化アルゴリズムを組み合わせており、このあたりの流れは後述します。
欲しい出力値を得るための入力値の探索をベイズ最適化で行う工程です。モデルの予測精度を上げるために、次に必要なデータの示唆を行うのが狙いです。
今回の探索ではここまでを行いました。
その後に知識モデルをデプロイし、次の制御仮設モデルを作り、知識モデルと連関して運用していこうという狙いです。
実現したい流れとしては以下のように1→2→3→4→1と検証サイクルを回転させ、知識モデルと組み合わせて自己学習的に運用することを目指しています。
1.[ 知識モデル ]現在わかっていることの体系(因果理解・構造化)
2.[ 制御仮説モデル ]目的性能を達成するにはどう制御すればよいか(予測・最適化・操作)
3.[ 実験・シミュレーション ](検証・更新)
4.[ 知識モデルの拡張 ]
ブラックボックス化する部分が確実に出てきます。なぜその予測が出るのか説明しづらく、「なぜその条件が最適なのか」が人間に直感的でなく、修正の妥当性や論理が見えにくくなる場合あります。
Google社提供のColaboratory(Colab)にて行いました。Colabはホスト型のJupyter Notebookサービスで、 クラウド上Python(特にデータサイエンスや機械学習)を気軽に実行できます。
Colabのシステムには、セッション(セッション=計算環境)が5つあり、5つの試験結果が同時に計算可能です。
各セッションには、マルチコア8個あり、フルで5セッションx8コア=40個の並列計算が可能です。今回、8コアを使って探索、机上実験を行いました。
表形式データ向けのディープラーニングモデルであるTabNetを用いました。このモデルは、各決定ステップでどの特徴量を使用するかを逐次的に選択する「Sequential Attention Mechanism(逐次注意メカニズム)」を採用しており、これにより高い解釈性と効率的な学習を実現しています 。
補完的にNODEを用いました。TABNETは、5個でもモデル精度の出せる優れものですが、今回TABNETで十分な結果を得られなかったため、補完的に用いました。
モデデル精度を出すには、実験データが少ないため、TABNETでデータの水増しを行い、NODEのモデル精度を出し、机上実験します。
実験データを5個 -> 1000個と、あくまで実験データ範囲内の水増しを行います。
NODEは線形回帰と深層学習の中間くらいの性能のもので期待しましたが、今回の試行ではよい結果を得られませんでした。
Optunaは、機械学習モデルのハイパーパラメータを自動的かつ効率的に最適化するためのPythonベースのオープンソースライブラリで、これを用いました。オープンソースですが、多目的最適化の最先端の数学コード(離散凸最適化、多様体最適化等)は非開示です。
ハイパーパラメータは、モデルの学習において、学習開始前にあらかじめ人が設定する外部の調整項目のことです。これに対して、「パラメータ」は、学習の過程でモデル自身がデータから自動的に最適化していく内部の変数を指します。ハイパーパラメータはモデルの性能や学習の安定性に大きな影響を与えるため、適切な値を選定することが重要で、これを自動で最適化するツールです。
完璧でなくとも、実用上十分に良い解を効率的に見つける手法で、これをOptunaに組み込んで部分的に用いました。数式による厳密な解法が難しい問題に対して、人間の経験的な“探索の知恵”を模倣したアルゴリズムを用い、近似的に良い解を探索するイメージです。
NSGA-III
多目的最適化において解の多様性を保ちつつ、非支配ソートで最良解を進化的に選ぶ手法。
MOEA/D
多目的問題を複数の単目的問題に分解し、それぞれを並列に最適化する進化的手法。
TPEs(TPE)
確率モデルを用いて有望な領域を重点的に探索する、ベイズ最適化ベースの手法。
各目的ごとに開発目標に達する仕様(解集合)を求め、その後、解集合のバランスを集合論を使い設計する手法です。Optunaは、解を発見しますが、セットベース設計法は、解を設計する。という感じです。
Optunaのアプローチに対して代替的に用いました。
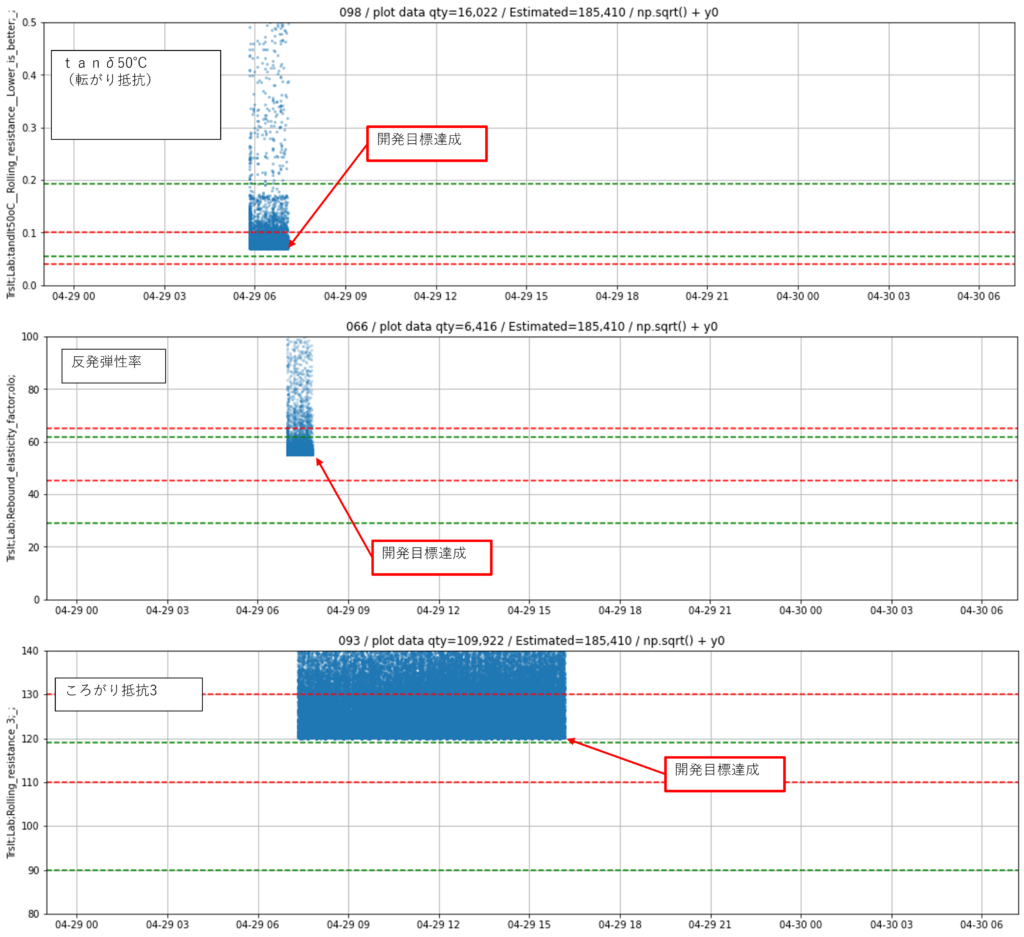
仮想実験を10万3000回実施し、示唆出しを試みました。結果11の開発目標をうち、まだ1つが達成できていない状況です。上記の試行錯誤はこの未達を踏まえて探索したためです。
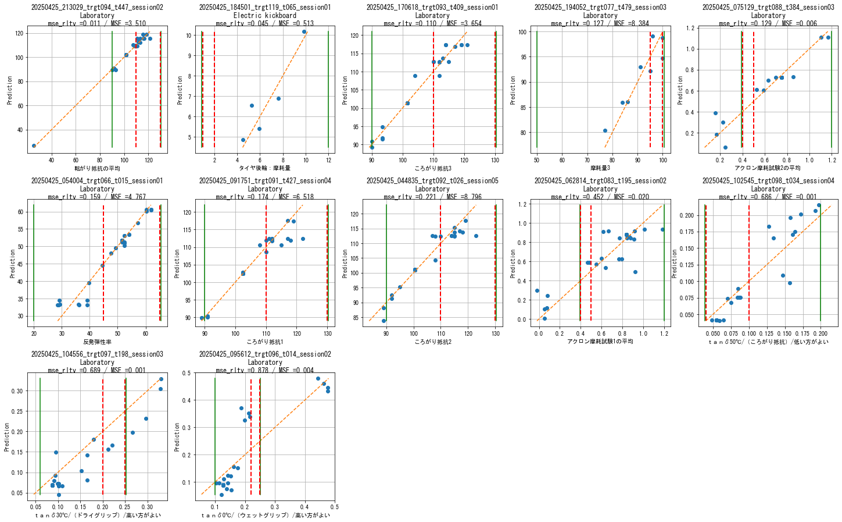
知識蓄積モデル(TABNETモデル) 試験結果のモデル近似
赤破線は、回帰線ではなく、1対1=45°線です。赤破線に載っているほどモデル近似できています。グラフは、上から右と、モデルの近似具合で並んでいます。
難易度は、必ずしも分野の特性とも限らず、どの分野も難問であり、人的な裁量でその成果は大きく変わってくる。なぜなら、以下のようなポイントが深層学習モデルの運用のポイントになるため。
1.データのない未知の領域を、いかに予測するか2.多目的最適化で、共通解のないところを、どう妥協していくか3.同じ環境(分析技術)を使っている競争市場において、いかに有意性のある結果を出していくか