
Exploring Deep Learning Processes: Using Marine Biodegradability Test Results of Rubber
May 20, 2025

Test results obtained from experiments on marine biodegradability of rubber samples were used in a search for the optimal compound that achieves both the required rubber properties and environmental performance by using deep learning processing. This is a detailed version of the oral presentation given at the annual conference of the Rubber Industry Association of Japan.
Toward Efficient Search
The goal of this project was to use deep learning processing of limited experimental data to generate promising suggestions for the next experiment. Based on the following assumptions in the development of tire rubber, we decided to use a deep learning approach instead of classical statistical inference or design of experiments.
Premise
- The number of experiments is limited to some extent in practice.
- In rubber properties for industrial applications, it is necessary to achieve multiple properties that are difficult to achieve together. In addition to multiple environmental performance, it is necessary to achieve multiple driving performance.
- Rubber manufacturing conditions depend on a considerable degree of factors
Differences in experimental design and inference
We decided to use deep learning because (1) it allows us to conduct (2) more complex studies from less data, and (3) it allows us to operate it in a learning fashion. The following are the differences between traditional statistical inference and experimental design and model-based development using deep learning.
| Human Insight | Classical Statistical Inference | Machine Learning-Based Inference | Deep Learning-Based Model Development | |
| Advantages | Cost | Statistically rigorous and easily passes classical peer review | Stable inference through large-scale data processing | Can generate insights beyond human expectations from limited experiments |
| Novelty of Inference | Present | Lacking (in novelty) | Limited (in novelty) | Present (novelty) |
| Data Volume (Number of Experiments) | Cannot handle even moderate increases in volume | Requires a moderate amount of data | Often requires a large amount of data | Recently, even small data volumes are sufficient; more is still better |
| Interaction Effects | Up to second or third order | Rarely covers higher than fourth-order interactions | Typically up to third-order interactions | Up to around ninth-order interactions (based on practical results) |
| Model Assumptions | Assumes a single cause and a single model | Assumes multi-causal models | ||
| Model Modification | Based on intuition and experience | Assumes a single cause and a single model | Flexible and adaptive through learning | |
| Unexpected Applications | Weak | Strong (against unexpected use) | Often weak (against unexpected use) | Strong (against unexpected use) |
| Disadvantages | Difficult to pass on human expertise | Rarely provides practically meaningful insights | Requires tedious feature engineering | Requires advanced data science for model construction and training |
Overall Framework
The overall framework is the following process
1.Experimental data and development goals
We took 87 factors from the experimental data consisting of experimental conditions and 11 priority items from the evaluation results to search for better conditions.
↓
2. Deep learning model for tabular data
Although some image data was used in the development, only the central tabular data was used in this case.

↓
3. Multi-objective optimization methods
Since there are multiple rubber and environmental performances to be achieved, a multi-objective optimization method was used. The methods are,
(1) Hyperparameter optimization of deep learning models
(2) Set-based design method
Since the target values could not be obtained with (1), (2) was used as a complement or alternative.
In (1), a heuristic optimization algorithm was combined, and this process is described below.
↓
4. Knowledge model preservation
↓
5.Desk Experiment
This is the process of Bayesian optimization to search for input values to obtain the desired output values. The goal is to suggest the next necessary data to improve the prediction accuracy of the model.
This search has been done up to this point.
↓
6. Deploying the Knowledge Model
The aim is to then deploy the knowledge model, create the next control tentative model, and operate in conjunction with the knowledge model.
↓
7. Search for control hypothesis model
The flow we would like to achieve is to rotate the verification cycle from 1→2→3→4→1 as follows, and combine it with the knowledge model to operate in a self-learning manner.
1.[ Knowledge model ] System of what is currently known (causal understanding, structuring)
2. [ Control hypothesis model ] How to control to achieve the target performance (prediction, optimization, operation)
3. [ Experimentation and simulation ] (validation and updating)
4. [ Extension of knowledge model ].
Demerit
There will certainly be areas that will become black boxes. It may be difficult to explain why the predictions are made, and it may not be intuitive to humans why the conditions are optimal, making it difficult to see the validity and logic of the modifications.
Execution Environments
We did it at Google’s Colaboratory (Colab), a hosted Jupyter Notebook service that makes it easy to run Python (especially data science and machine learning) in the cloud.
The Colab system has 5 sessions (session = computing environment), which can compute 5 test results simultaneously.
Each session has 8 multi-cores, so a full 5 sessions x 8 cores = 40 parallel calculations are possible. This time, we used 8 cores for exploration and desktop experiments.
Details of each process
Processing Tabular Data: TABNET
We used TabNet, a deep learning model for tabular data. The model employs the Sequential Attention Mechanism, which sequentially selects which features to use at each decision step, resulting in high interpretability and efficient learning.
Complementary NODE
NODE was used as a complement to TABNET, which is an excellent tool that can produce model accuracy with as few as 5 pieces, but TABNET did not produce sufficient results in this case.
To achieve the modeling accuracy, since the experimental data was too small, we padded the data with TABNET to achieve the NODE modeling accuracy, and conducted a desk test.
The experimental data will be padded from 5 -> 1000 data, which is only within the experimental data range.
We expected NODE to have a performance somewhere between linear regression and deep learning, but we did not get good results in this trial.
Multi-objective optimization: Optuna
We used Optuna, a Python-based open source library for automatically and efficiently optimizing hyperparameters in machine learning models. Although open source, the state-of-the-art mathematical code for multi-objective optimization (discrete convex optimization, manifold optimization, etc.) is not disclosed.
Hyperparameters are external tuning items in the training of a model that are set by a person in advance before the start of training. In contrast, “parameters” are internal variables that are automatically optimized from data by the model itself during the learning process.
Since hyperparameters have a significant impact on model performance and learning stability, it is important to select appropriate values for them, and this tool automatically optimizes them.
Heuristic Optimization Algorithms
It is a method for efficiently finding a solution that is good enough for practical use, if not perfect, and is partially used by incorporating it into Optuna.
For problems that are difficult to solve exactly with mathematical formulas, an algorithm that mimics human empirical “search wisdom” is used to search for a good solution in an approximate manner.
NSGA-III | A method of evolutionary selection of the best solution by non-dominated sorting while preserving solution diversity in multi-objective optimization. |
MOEA/D | An evolutionary method that decomposes a multi-objective problem into multiple single-objective problems and optimizes each of them in parallel. |
TPEs(TPE) | A Bayesian optimization-based method that uses stochastic models to focus on promising regions. |
Multi-objective optimization method 2: Set-based design method
Optuna finds a solution, while the set-based design method designs a solution. Optuna finds the solution, while the set-based design method designs the solution.
We used this method as an alternative to the Optuna approach.
Results
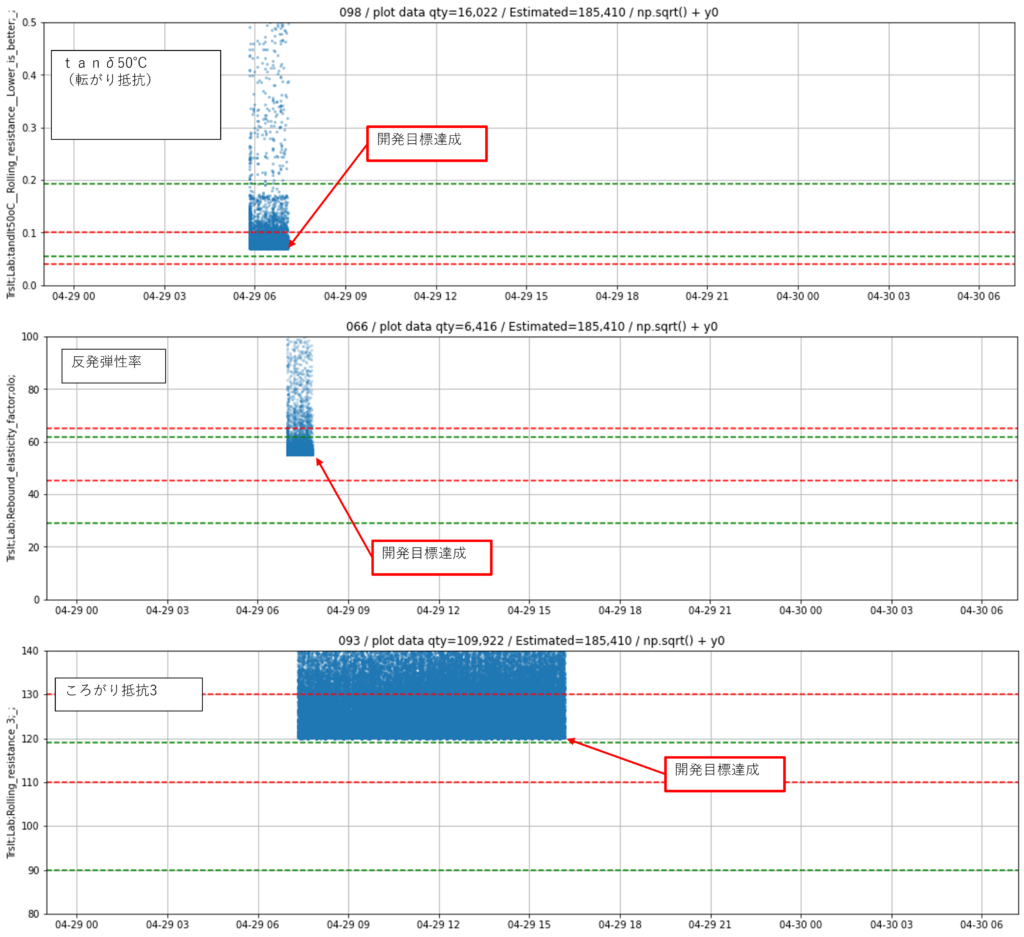
We have conducted 103,000 virtual experiments and attempted to make suggestions. As a result, of the 11 development goals, one has not yet been achieved. The above trial and error is due to our search based on this unachieved goal.
- Experimental Data and Development Goals
- Deep learning model for tabular data
- Multi-objective optimization method
- Knowledge model storage
- Desk top experiments ★ We have progressed to this point.
- Deploy knowledge model
- Exploration of control hypothesis model
The results suggest the use of more material at a single point, which was not assumed. However, verification based on this suggestion has not yet been performed.
Knowledge accumulation model (TABNET model) Model approximation of test results.
The red dashed line is not a regression line, but a one-to-one = 45° line. The higher the red dashed line is, the better the model approximation. The graphs are arranged from top to right according to the degree of model approximation.
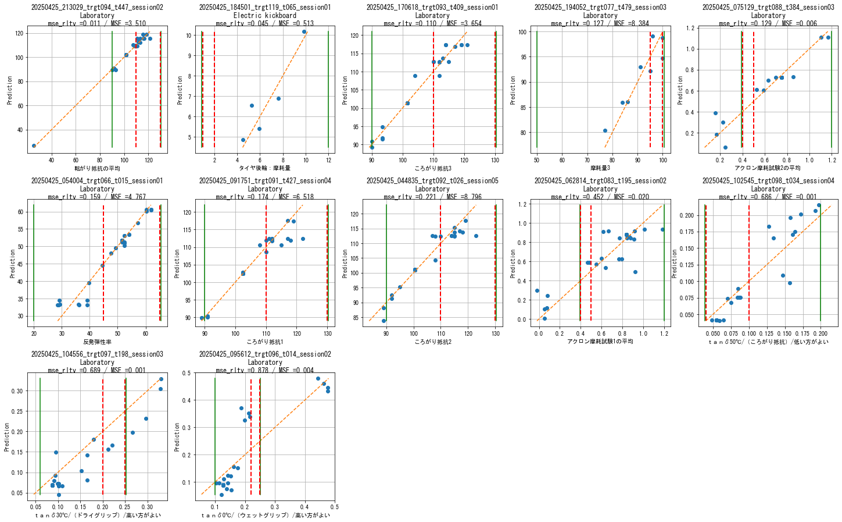
My impression so far is that
Potential applications in this field
- Re-experimentation is time consuming and implementing so-called adaptive design of experiments is not easy in this field.
- In fact, there are many factors that are not included in the tabular data, and in this respect, it will take time to ideally apply deep learning and realize futuristic concepts such as Agentic AI in the rubber manufacturing field.
- Efforts to prepare more comprehensive data sets are needed. The more knowledge and expertise of the analysts, workers, and planners overlap, the easier it will be to be effective.
Necessary perspectives for deep learning applications that are important regardless of the field
The degree of difficulty is not necessarily a characteristic of the field, but all fields are challenging, and human discretion can make a big difference in their outcomes. This is because the following points are key to the operation of deep learning models.
1. how to make predictions in unknown areas where no data is available
2. How to compromise where there is no common solution in multi-objective optimization
3. How to produce significant results in a competitive market using the same environment (analysis technology).
Is general-purpose software viable?
- Data analysis technology itself is in a transitional stage of innovation by AI, and it will be quite difficult to realize general-purpose software and SaaS.
- The day after a paper is published, we can try out a Python code, and it will become obsolete before it is compiled in a compiled language.
- We have no choice but to take a tailor-made approach.